深度学习入门
Monday, August 21, 2023
deepin 社区官方博客
 #deepin-community:deepin.org
#deepin-community:deepin.org
背景
从去年底以来,AIGC 炙手可热,多个业界大佬都认为 AIGC 会给整个产业带来一场革命,甚至所有的软件都会用 AI 重写。从历史上来看,人机交互方式的变革往往会将操作系统带入下一个世代,著名的例子如从命令行界面的 DOS 到键鼠图形界面的 Windows,以及带来触控界面的 iPhone,领创者都成为了世界顶级企业,带动了整个生态的发展。
从技术上来看,AIGC 是基于大模型的,而大模型的基础是深度学习,因此,为了在产品上结合 AIGC,首先从技术上首先需要对深度学习进行有深度的学习。
对深度学习与大模型的探索将由一系列文章组成,本文是系列里的第一篇,主要关注的是深度学习的技术入门探索。
从神经元开始
回溯历史,深度学习起始于向人类的大脑学习如何学习。人类大脑皮质的思维活动就是通过大量中间神经元的极其复杂的反射活动,因此不妨先看看神经元的工作机制。
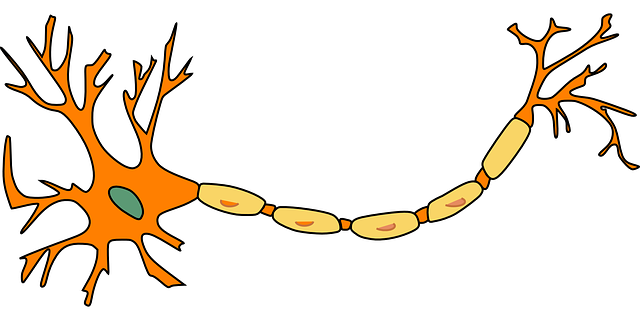
图1 神经元结构
图1给出了神经元的大体结构,左边是神经元的主体,其输入是左侧的多个树突,其输出是右侧的一个轴突。只有当输入树突的信号足够强烈的时候,输出轴突上才会有信号产生。受此启发,就可以设计一个最简单的有两个输入x1与x2,以及一个输出y的线性函数来模拟单个神经元,引入阈值θ,当 w1x1 + w2x2 ≥ θ时,y为1(表示有信号),否则y为0(表示无信号)。其中w1与w2分别是x1与x2的参数或权重(weight)。
有了这个函数,下面来看看它究竟能做什么。按照逻辑主义的设想,数学可以通过逻辑推衍出来,那么不妨看看,上面的函数是否可以表征出基本逻辑运算,如与、或、异或等,在这里x1、x2与y的取值都只能是0或1。
对于逻辑与来说,只有当x1与x2都是1的时候,y才是1,否则y是0,容易尝试得到一组可能的w1、w2与θ,分别是0.5、0.5与0.7,如图2所示。
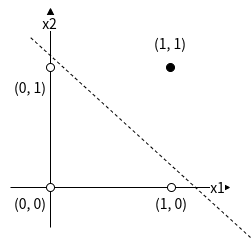
图2 逻辑与的线性函数图
图2中横轴为x1,纵轴为x2,从图2中可以看到,(1, 1) 点为实心圆,表示y为1,在(0, 0)、(0, 1)与(1, 0)都是空心圆,表示y为0,中间的虚线表示w1x1 + w2x2 = θ这条直线,只要这条直线能将(1, 1)点与其它点划分到不同区域,则显然就可以找到至少一组w1、w2与θ满足条件。基于同样的分析,容易知道逻辑或也可以找到对应的w1、w2与θ。但是对于逻辑异或来说,问题就严重了,显然无法找到满足条件的w1、w2与θ,如图3所示。

图3 逻辑异或的函数图
逻辑异或是当x1与x2中一个为0,另一个为1时y才为1,否则y为0,因此在图3中,点(0,1)与点(1,0)为实心圆,而(0, 0)与(1, 1)为空心圆,显然是无法找到一条直线将两个实心圆与两个空心圆划分在两个不同区域的。因此,上述最朴素的线性神经元函数无法表示逻辑异或,也就意味着有大量的运算无法通过上述线性神经元函数来进行。
引入激活函数
是否能改造上述函数,让它能支持所有运算,从而能承担学习的任务呢?至少,人脑肯定是能学会异或的。现在看来,主要是因为原始的神经元函数太线性导致的这个问题。因此,在深度学习中,就引入了非线性的激活函数(activation function),如图4所示。

图4 引入激活函数
在图4中,首先原函数被修改成了支持多个输入和多个输出的线性变换函数,这样就能处理更多种类的问题了。因为有了多个输入x1、x2…xm与多个输出h1、h2…hn,因此权重的下标也带有两个数字,以表示每个权重的作用,例如 w12 是输入x2与输出h1间的权重。还有一个特殊的权重bi,它被称为偏置(bias),是一个待确定的常数项。这样,h就等于相应的x与w相乘后再加上b。例如,hi = xiwi1 + x2wi2 + … + xmwim + bi。 经过线性变换后得到的输出h1、h2…hn只是中间过程的输出,在之后,还需要加入一个非线性的激活函数的处理,以得到最终的输出y1~yn,如图4所示。
在具体激活函数的选择上,比较常见的有 softmax、sigmoid 与 relu 等。其中 softmax 函数是多分类问题最常用的输出激活函数(多分类问题指的是一个问题有多个确定个数的可能答案,例如是/否问题是二分类问题,而分辨一个手写阿拉伯数字是哪个数就是一个十分类问题,因为可能答案有0~9一共十个),softmax也是包括ChatGPT在内的大模型使用的输出函数。 使用了激活函数以后,神经网络就可以学习到所有函数了。下面来看一个经典的神经网络的例子,手写数字识别问题,或MNIST问题。MNIST涉及的手写数字在网上是公开的,如图5所示。程序员们可以先想想,如果自己来写一个程序识别手写数字会怎么写。可以识别手写数字的(一个)神经网络的结构如图6所示。

图5 MNIST手写数字样例
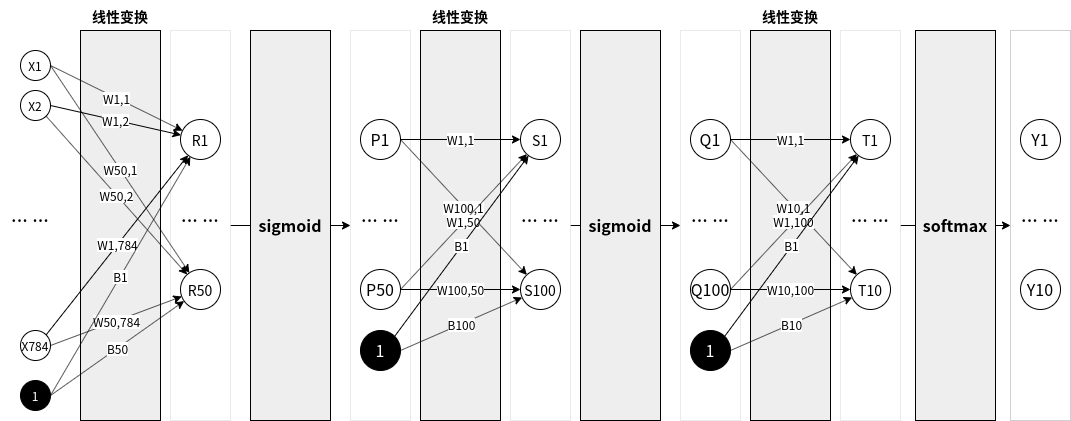
图6 能识别手写数字的神经网络
可以看到图6的神经网络一共用到了三个线性变换,并使用了两个sigmoid 激活函数,以及最后的softmax激活函数,因此可以说这个神经网络是三层的。神经网络的输入(x1~x784)是一个长度为784的数组,其实就是一个28x28=784的手写数字的黑白图像。神经网络的输出(y1~y10)分别代表了0~9的阿拉伯数字,这是一个典型的十分类问题,因此使用softmax也是非常自然的。
图6中的神经网络一共有(784x50+50) + (50x100+100) + (100x10+10) = 45360个参数,对比ChatGPT上千亿个参数,这显然是一个微模型,但是它的识别能力却可以达到92.53%,也就是说一万个手写数字,它能正确识别出9253个来。 那问题就来了,这45360个参数是怎么来的呢?肯定不能是随便什么 45360 个数都能带来这么高的识别率的,要解决这个问题,就需要看看神经网络是怎么学习的了。
神经网络的学习
在上面已经看到,神经网络里有大量的参数。在最开始,这些参数会被随机分配一些数字(当然如何随机分配也有讲究的,简洁起见,此处先不提),此外也需要准备大量的数据,这些数据一般是多个输入输出的对(x, t)。例如在上面的手写数字识别问题中,输入x就是一个28x28的手写数字图像,输出t就是这个图像对应的0~9中的一个数字。 这些数据会被分成训练集与测试集。训练集中的数据用来训练神经网络,让神经网络中的参数最终达到正确的值。测试集中的数据用来测试训练后的神经网络,对比看训练后的神经网络在新的数据下得到的结果是否正确。
神经网络的训练过程可以大体分为下面几步:
对训练集中的输入输出对(x, t)进行如下处理
将x输入到神经网络中,计算得到y
将y与正确的输出t进行运算得到损失L,损失的计算函数一般是均方差或交叉熵,前者针对的是回归问题(连续函数拟合),后者针对的是分类问题
根据L调整神经网络的参数,调整的方向是减少L,调整的方法是下面要讲的反向传播
图7给出了神经网络训练的过程。
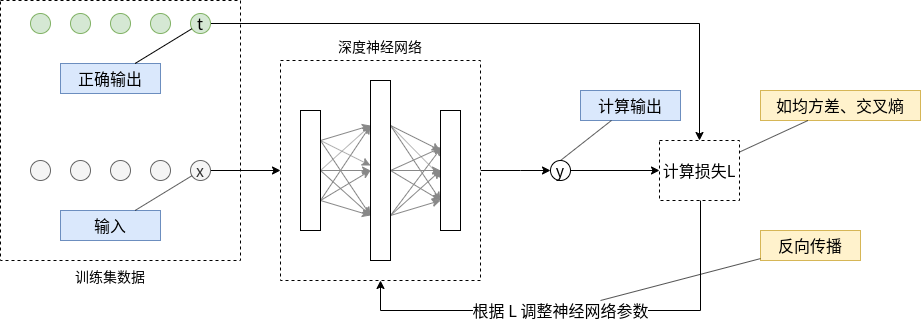
图7 神经网络训练过程
一旦训练完毕,使用的时候就不需要正确输出t,也不需要计算损失L和调整神经网络的参数了,这个过程被称为推理(inference),如图8所示。
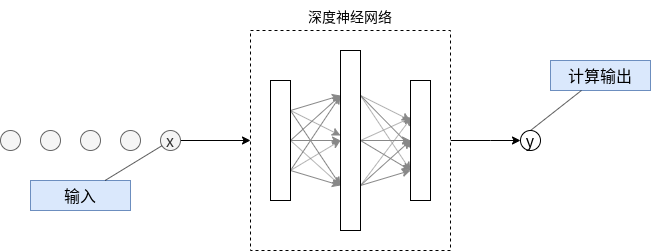
图8 神经网络推理过程
顺便说一句,图中的深度神经网络与神经网络结构是一样的,但是层数较多,因此被称为深度神经网络。
下面,再来看看神经网络究竟是怎样通过损失L来调整网络参数的。最简单,也是最直观的方法就是将每个参数都稍微调大或者调小一点,看L会如何变化,如果L变小,则保持此参数的调整,如果L变大,则将此参数反过来调整。以上即正向调整法,思路清晰,操作方法简单,但是计算量极大,因为每调整一个参数就要重新计算一遍y与L。
另一种方法就是现在主流的反向传播(BP,backpropagation)法,此方法类似系统发生故障时的根因分析,首先分析最后一层的参数是怎样影响到L的,然后分析倒数第二层的参数是如何影响到最后一层的输入的,如此类推。在数学上,其实就是计算L对某个特定参数w的(偏)导数,因为导数就代表了w的变化会导致L如何变化。根据链式求导法则,L对w的导数等于L对中间变量h的导数乘以h对w的导数,前者相当于计算最后一层参数的导数,后者相当于计算倒数第二层参数的导数,两者相乘即为L对导数第二层参数的导数。
下面主要通过求导来展示反向传播,如果希望更直观一点,可以阅读计算图相关的资料。假设真实函数是y=2x+1,则待求函数为wx+b(当然w与b的真实值应该是2与1)。下面通过一组数据(训练集)来通过反向传播逐步计算更新w与b,看看它们否会逐渐逼近2与1。
由于这是一个回归问题,因此使用均方差(y-t)< sup>2< /sup>/2作为损失L的函数,显然L对y的导数是y-t,参数更新使用经典的梯度下降法(SGD),即参数新值=参数旧值 - 学习率x(L对参数的导数),梯度下降有一个粗糙但是直观的理解,那就是学习应该向着导数(梯度)相反(下降)的方向走,在这里学习率这个参数设为0.01。
首先,将w与b随机化为0.5与0.6。
假设第一个训练对为(0, 1),则 y = wx + b = 0.5·0 + 0.6 = 0.6,L对w的导数=L对y的导数乘以y对w的导数=(y-t)·x=(0.6-1)·0=0,L对b的导数=L对y的导数乘以y对b的导数=(y-t)·1=-0.4。则w的新值为w-0.01·0=0.5,b的新值为b-0.01·(-0.4)=0.604,显然新的w与b比原来的更接近(2, 1)。
若第二个训练对为(1, 2.9)(本来应为1与3,但是增加了一点误差干扰),可以以同样的方法得到新的w为0.51796,而新的b为0.62196,显然比上一对w与b又接近了2与1一点。
实际上,若继续增加2x+1附近的数据,可以发现到了十几对训练数对之后,w与b即可相当接近2与1了。
以上例子是为了直观感受反向传播的计算而给出的,实际上这种线性函数的回归可以通过数据集基于矩阵一次性算出来,而且训练本身也要考虑收敛的问题,因此实际的深度学习会更复杂一些,但是原理是类似的。
总地来说,深度神经网络是由多个层组成的,每一层均有前向(forward)推理的函数,用来从输入计算得到输出,这个过程即为推理。每一层也有反向(backward)传播的函数,用来从后一层传来的导数计算得到本层向前一层传递的导数,并同时更新本层的参数。如果是训练,则需要在最后一层再加上一个输入为t与y的损失层,输出为L,如图9所示。

图9 多层神经网络结构
通过以上几乎标准化的神经网络层,深度学习的研究者就可以像搭积木一样对多个层进行排列组合,得到多种多样的深度神经网络,并首先通过反向传播训练出神经网络的参数,继而使用神经网络进行推理应用了。